Normalize
What It Does
Standardizes text by applying Unicode normalization and optionally removing diacritical marks (accents). It ensures consistent text representation regardless of how characters were originally encoded.
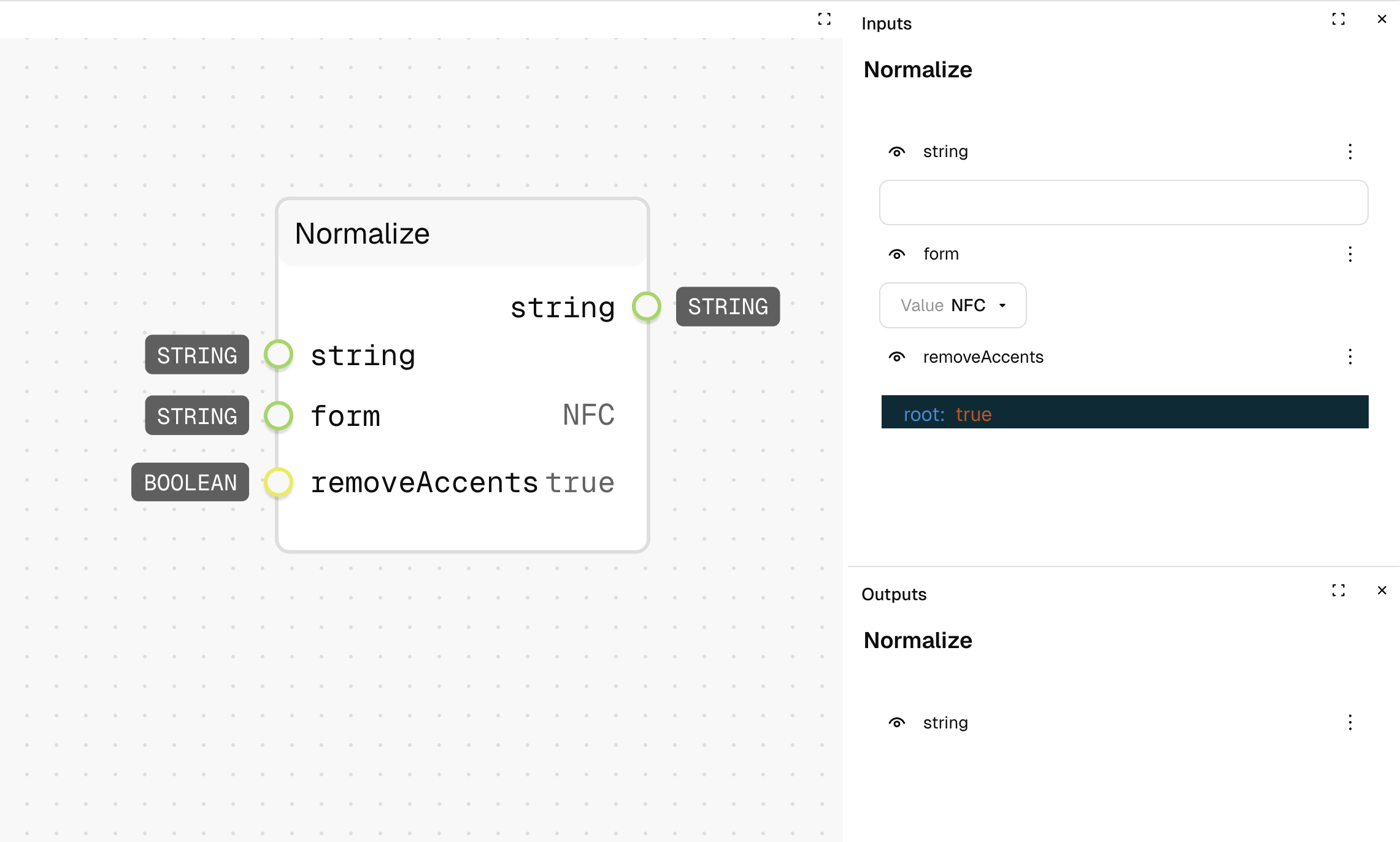
Inputs
| Name | Description | Type | Required |
|---|---|---|---|
| string | The text to normalize | String | Yes |
| form | The Unicode normalization form | String | No |
| removeAccents | Whether to remove accents from characters | Yes/No | No |
Outputs
| Name | Description | Type |
|---|---|---|
| string | The normalized text | String |
How to Use It
- Drag the Normalize node into your graph.
- Connect the text you want to normalize to the "string" input.
- Select the desired normalization form (NFC, NFD, NFKC, or NFKD).
- Set "removeAccents" to true if you want to remove diacritical marks from characters.
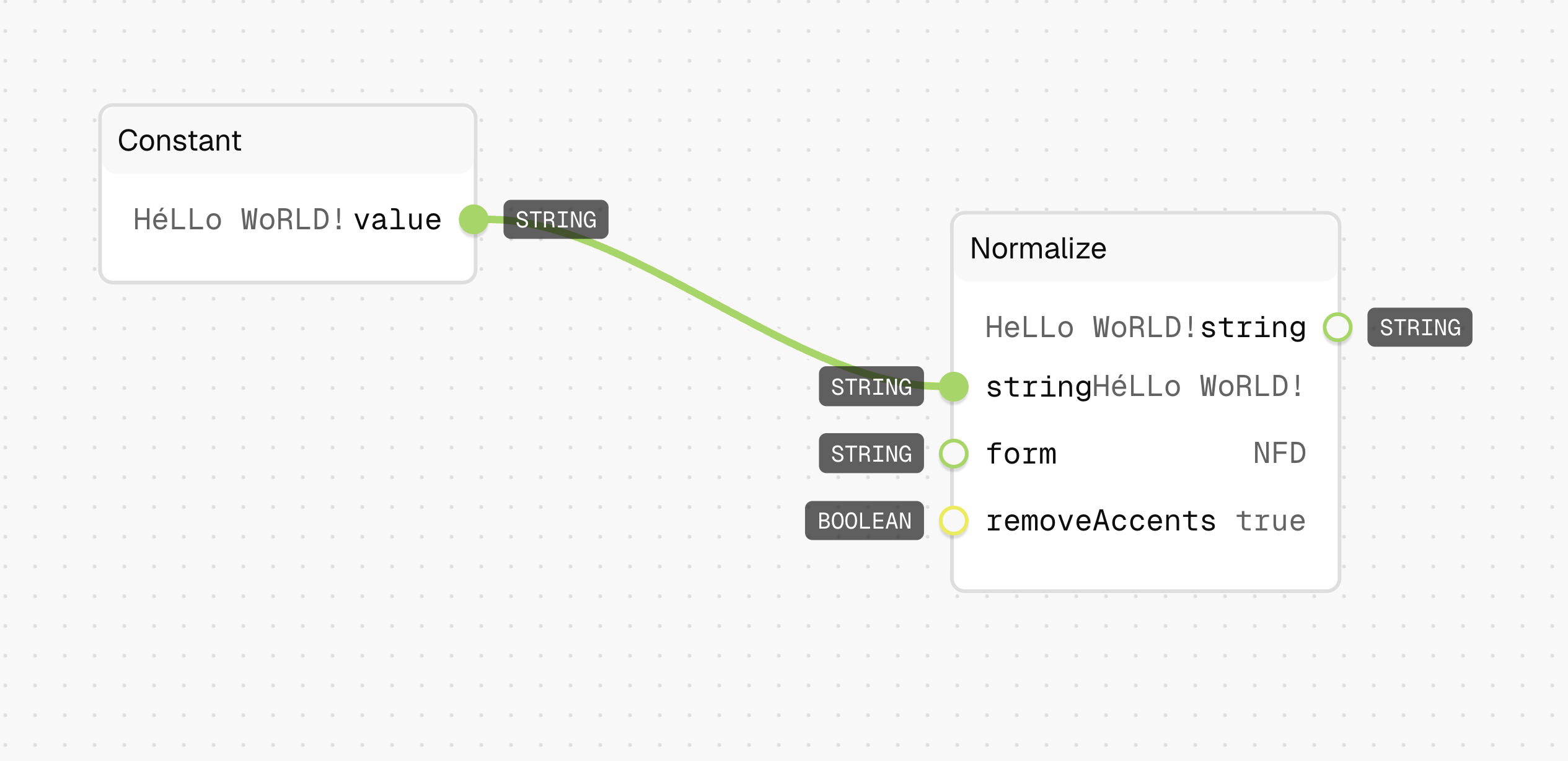
Tips
- Use NFC (default) for most general text normalization needs.
- Setting "removeAccents" to true will convert characters like "é" to "e" while preserving the base character.
See Also
- Case Convert: For changing between different text case formats.
- Regex: For more advanced text transformations using regular expressions.
Use Cases
- Search Optimization: Normalize text for more accurate searching across accented and non-accented versions.
- Internationalization: Standardize user input from different languages and character sets.
- URL Generation: Create clean, accent-free slugs for web addresses from international text.